
So I’ve decided to spill the beans on some of the cool things we do at HUGECITY to get all those delicious events and event recommendations to you. Here we go with part one of a series of tech showcases: HUGECITY Secret Sauce.
Bragging point: We had ticket links for Facebook events a few months before Facebook rolled them out as a page and API feature. We automatically detected and promoted ticketing links for over 2 million event listings.
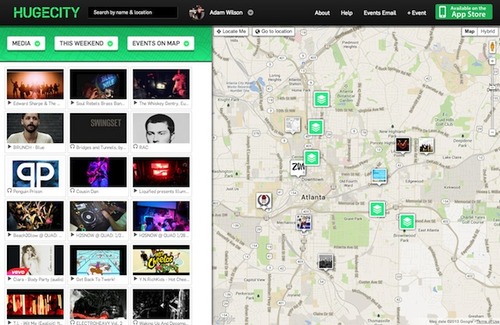
Another bragging point: One of the less-used features of HUGECITY is what I like to call the ‘Media Cloud’. It’s a somewhat-experimental feature where we show all the media (videos and sounds) associated with events on a date in an area. Check it out by changing the events pull-down to media on HUGECITY.
How did we do this? Simple, we scanned the description and comments feed for every event we indexed and determined if they contained links that pointed to a ticketing site’s page for an event. Of course it’s really not that simple, it’s fetching several million web pages and determine if they sell tickets. Oh, and as an added challenge OVER HALF of them are behind those wonderful link shorteners that make analytics mavens cheer and web engineers cry.
We needed a solution with which we could quickly get the metadata for any link that we found in an event. That’s a lot of distributed page loading and analysis, and our little Ruby on Rails stack couldn’t handle it without a pretty massive scale-up. I’d built a couple of simple apps and tools in Node.js and thought that page metadata grabbing was a wonderful application for it. A few days later we had:
The Peekr
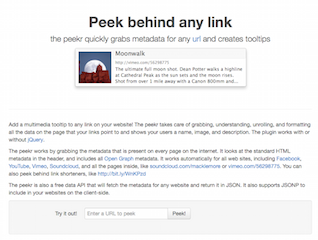
The Peekr started out as just a web service to grab the metadata for any page. With Facebook and Twitter, the amount of easily machine-readable data in the meta tags of any given web page’s header has gotten pretty impressive. Web designers and editors want to maximize the shareablity of their sites, so they embed the opengraph tags so that whenever someone shares their site in Facebook, it looks nice and pretty.
The Peekr simply pulls down those relevant meta fields. For example, when you ask the peekr for the metadata for facebook.com, you get
{
"image": "https://www.facebook.com/images/fb_icon_325x325.png",
"title": "Welcome to Facebook - Log In, Sign Up or Learn More",
"description": "Facebook is a social utility that connects people with friends and others who work, study and live around them. People use Facebook to keep up with friends, upload an unlimited number of photos, post links and videos, and learn more about the people they meet.",
"url": "https://www.facebook.com/"
} in about 250 milliseconds. Neat.
Also, but to maximize the shareability, sites like Youtube and Vimeo embed lots more information than that in their metadata. At the time of this writing, one of the videos on the front page of Vimeo was A Short Story About Hands, which presents all this lovely data through the peekr:
{
"title": "A Short Story About Hands",
"description": "Written and Directed by Casey Donahue. http://thecaseydonahue.com/shortstories",
"image": "http://b.vimeocdn.com/ts/439/000/439000905_1280.jpg",
"type": "video",
"video": "http://vimeo.com/moogaloop.swf?clip_id=67207222",
"video:secure_url": "https://vimeo.com/moogaloop.swf?clip_id=67207222",
"video:type": "application/x-shockwave-flash",
"video:width": "640",
"video:height": "360",
"site_name": "Vimeo",
"url": "http://vimeo.com/67207222"
}Yup, that’s an embeddable movie link right there. We use that to populate the media listings for the site and show thumbnails for all the media for events on the event pages.
Can this thing go faster?
Yes it can! The first parser I built started to choke at 50+ simultaneous requests on 1 Heroku dyno. It was a simpistic DOM parser that had to instantiate the ENTIRE html document in memory (in addition to the source text). Of course, the content that I wanted was usually all in the HEAD section, so ~95% of the server’s capacity was completely wasted. Given that one event can have 20+ links in its body and we process 1000’s of events at a time, that load limit was unacceptable.
Since Node.js is evented, I wanted to build the parser in an evented way. Fortunately, there’s a great SAX parser for Node. It was easy to write just the event handlers I wanted and pipe the HTTP response through it. Now nothing larger than the request, response, and buffers sits in memory for each request.
Also, I initially used IronCache to store the metadata for pages after they were fetched to speed things up, but less than 1% of requests actually hit the cache in real usage. The peekr just grabs the page every time now.
Very cool, but there’s nothing to show people.
One of the sad things about creating a simple service is that there’s nothing visual to show people. So I made a javascript library to show the metadata as a tooltip. Try hovering over this link:
Or any other link on the page if you haven’t noticed the tooltips. Attaching the previews with jQuery was as easy as:
1
2
3
4
<script src="http://js.thepeekr.com/peekr.js" type="text/javascript"></script>
<script type="text/javascript">
$(document).ready(function() {$("a").attachPeekr()})
</script>